
【発酵デザイン入門】生命のデザイン? 遺伝子組換えとゲノム編集を分解するDay5
生命をデザインすることで、人間は「神」になるのだろうか…?
発酵の概念を拡張し、暮らしにまつわるバイオテクノロジーを包括的に学ぶgreenzの講座『発酵デザイン入門』第五回の講座レポートをお届けしまーす。最終回は、微生物や細胞よりもさらにミクロな「DNA/遺伝子」の世界に迫ります。。過去のレポートは以下から。
・【発酵デザイン入門】発酵で社会をよりよく!未来の科学のリテラシーを考えるDay1
・【発酵デザイン入門】発酵なくして人類の文化なし!食と暮らしのテクノロジーを深掘る Day2
・【発酵デザイン入門】生命のミクロの秘密を顕微鏡で覗こう!生物のデザインを紐解く Day3
・【発酵デザイン入門】微生物が地球をつくった。 ミクロの生態系を探るDay4<前編>
・【発酵デザイン入門】お腹のなかの驚異の生態系。 腸内細菌と免疫のひみつに迫るDay4<後編>
DNA=生命の設計図
最終セクションは、遺伝子のデザインをみんなで学びます。
日常生活でもよく比喩として使われる「DNA」とは何なのか。
基本的な定義は上記の通り。

1950〜60年代にかけて、「DNAおじさん」ことイギリスの微生物学者フランシス・クリックによってその構造がモデル化され「生命のセントラル・ドグマ(中心理論)」としてまとめられました。じゃあ、その理論ってどういうことなの…?
すいません、まだ『逃げ恥』ネタ引っ張ります(平匡さん…!)。
DNAとはつまり「生命というアプリケーションを記述する統一文法」のようなものだと思ってください。
「文法」と表現したものの、DNAはヴァーチャルなものではなく実際に存在している物質でもあります(←目に見えないけど)。ではその構造はどうなっているのかというと…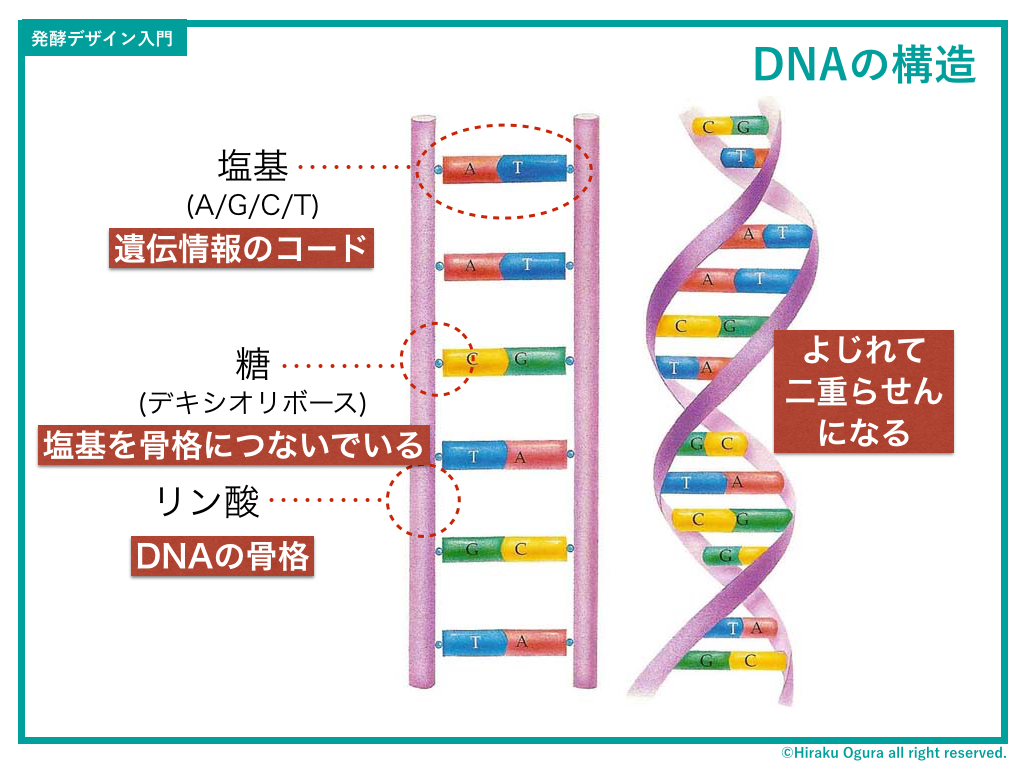
このように、リン酸がつながってできた骨格のあいだに、塩基と呼ばれる物質がペアになって挟まれ、リン酸と塩基の2つを糖が接着しているという構造になっています。
ちなみにリン酸は、生命のエネルギー通貨であるATPの重要な構成要素でもあります(詳しくはDay3参照)。
ポイントは3つ。
1:塩基は必ずペアになって結合している
2:骨格がよじれて二重らせん状になっている
3:DNA自体が直接働くことはない
1の理由:ペアにすることで、らせんを2つに分割して複製することができる
2の理由:らせんをほどいて複製しやすい&複数のらせんをよりあわせて糸状にしやすい
3の理由:直接働くと構造が壊れて複製できなくなる
いっけん不可思議に見える構造ですが、実はDNAは非常に合理的にデザインされています。
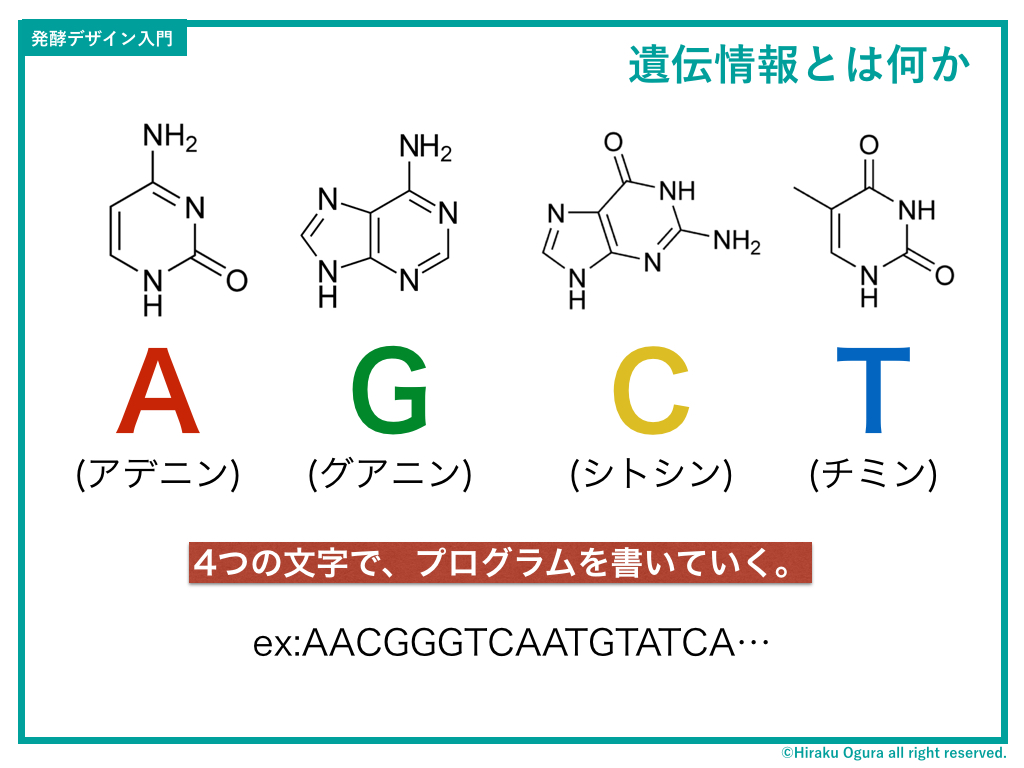
ではより詳細に解説していきましょう。
前述の「塩基」について。この塩基には4つの種類があり、それぞれA(アデニン)、G(グアニン)、C(シトシン)、T(チミン)と言い、基本的には同じような材料(原子)から作られていますが、そのデザインが違います。
※ちなみに「塩基」の定義は電子を受け取る(酸化される)アルカリ性の受容体であること(と書いても化学やっている人じゃないと意味わからないが)。
この4つの塩基がつまり「遺伝子というプログラムを記述するためのアルファベット」。
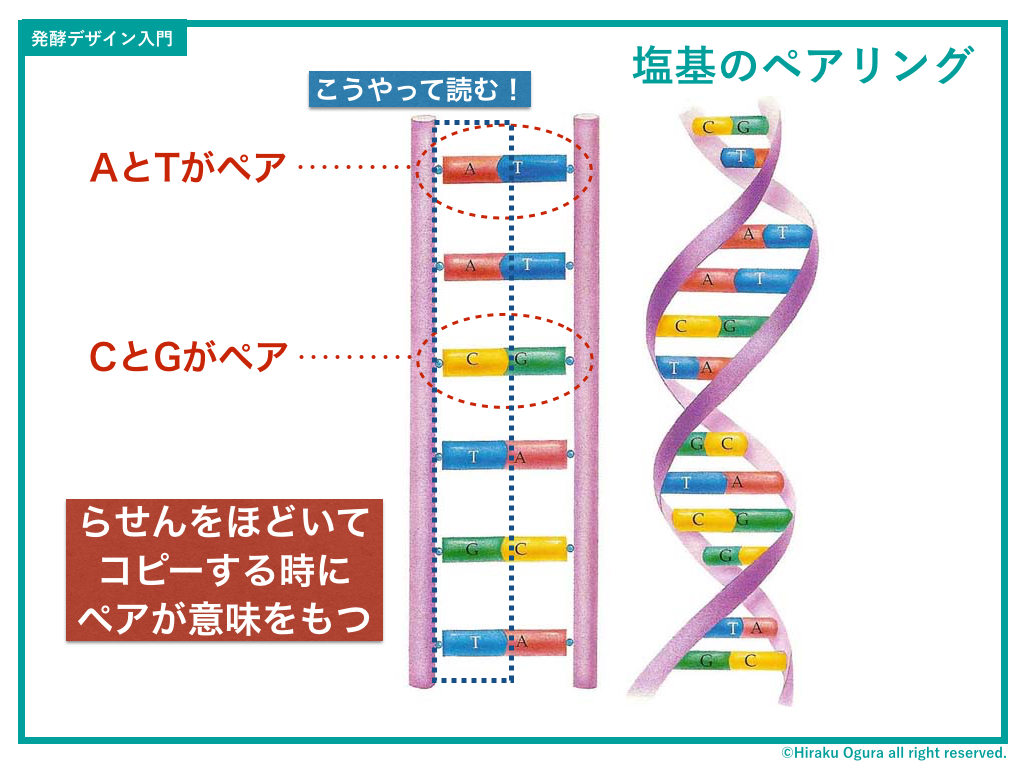
らせん骨格のあいだに2つの塩基がペアになって挟まっているのですが、このペアは必ず
・AとTがペア
・CとGがペア
というルールで結合しています(なぜなら2つがペアになることにより、分裂して複製するときにミスが起きにくくなるから)。
遺伝子情報とはAGCTATGCCCTA…のように、塩基の連なりで記述されます。で、その読み方なんだけど、上の図のように、ある一方を縦に読んでいくんですね。
図では、左列を読んでAACTGTとなっていますが、右列を読むとTTGACTとなります。この2つの記述は、実は同じ(ペアになっているからね)。
後述しますが、DNAが複製される時はこの「左右のペアリング現象」に基づいて情報がコピーされるのです。
「うおーッ!すげー難しいッ!で、結局オレっちの遺伝子はどんな感じなわけ?」
そうね。
まず前提として遺伝子情報ってのは、AACTGTATGCCCTAGTGC…という感じで4つのアルファベット(塩基)で記述されるプログラミングコードなのね。
で、人間の全遺伝子情報は約32億文字で書かれている。データ量に換算すると、32億×2ビットで64億ビット。8ビットで1バイトなので、8億バイト=800MB=CD-R一枚ぶん。文庫本が一冊400KBなので、文庫本約2,000冊。
一日一冊読破したとして、全部読み終えるまでに6年かかる!それがヒト細胞の中心にある核の0.01mのなかに収まっているのだからその情報の圧縮度たるや、mp3とかjpegとか比較にならんですタイ!
「えっ、オレっちの各細胞のなかに32億文字の情報が収まっているわけ?」
そうそう。人間の細胞はだいたい全部で1兆個と言われているので、800MB×1兆=80,000,000TBだからお台場あたりのサーバールーム2〜3部屋は必要なんでないの(僕、沼田さんじゃないからわかんないけど)。

さて。ここでちょっとDNAに関するボキャブラリーの整理。
DNAとは「構造体=文法」を指し、その文法で記述されたコードを遺伝子と呼ぶ。そしてある生物における全ての遺伝子情報を合わせたものをゲノムと呼びます。
さらに、DNAを写し取ったCC(カーボンコピー)のようなものをRNA、遺伝子がいっぱい寄り集まった糸状の物質を染色体と言います(どちらも詳細は後述)。
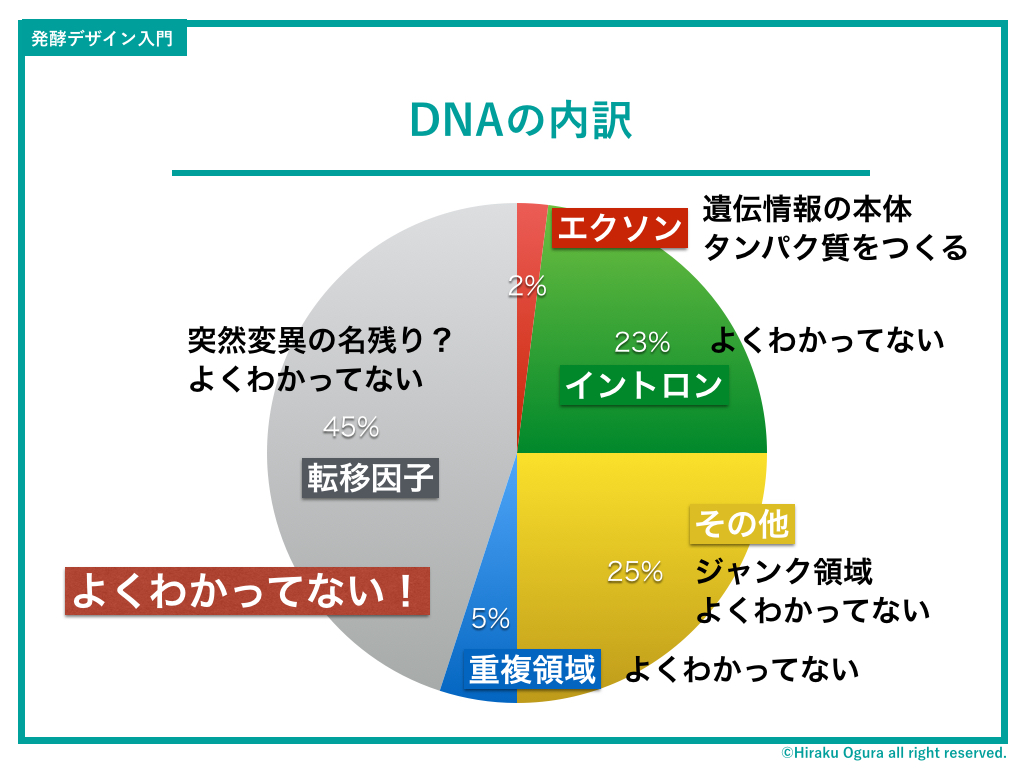
DNAで記述される情報(文字列)には種類があります。
で、そのなかで「ちゃんと機能を持っている部分=エクソン」はたったの2%。残り98%は「機能してない」あるいは「何してるのかよくわかってない」という状態になっています。
プログラミングに例えて言えば、本体のhtml部分はなんとなくわかっているんだけど、cssとかjavaの部分はぜんぜんわからん!みたいな感じかもしれません。
特に45%を占める『転移因子』は謎が多く、ある種の仮説によると「遺伝子の突然変異の名残が蓄積した部分」だとも言われています。謎…!
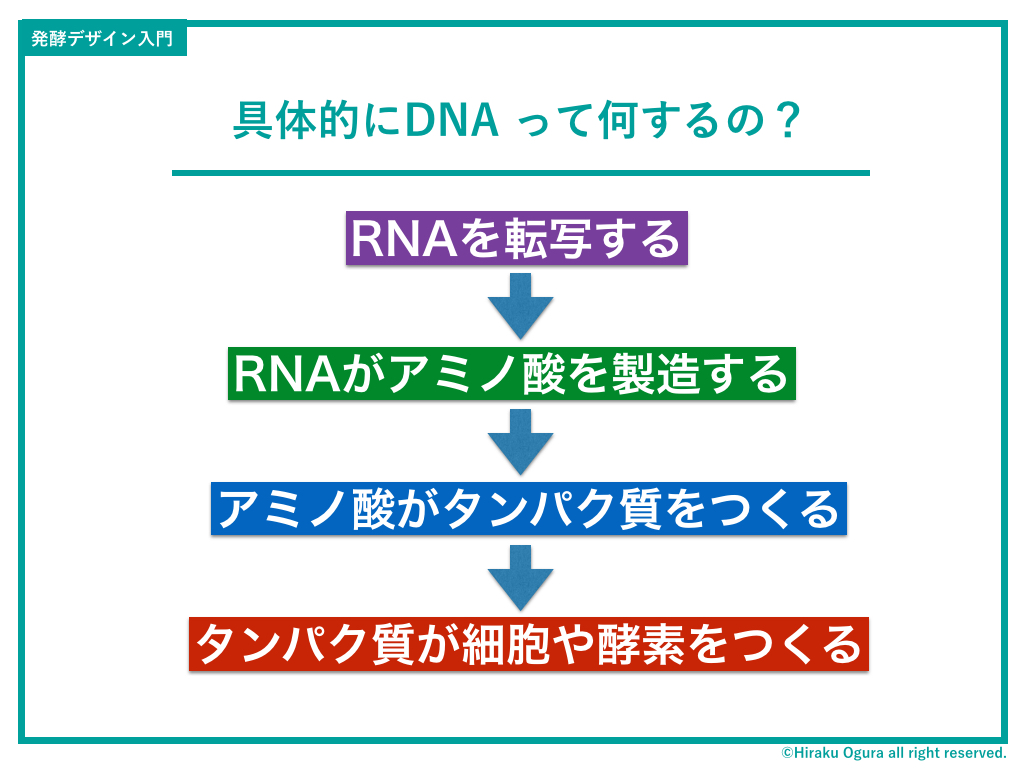
さてではそのDNAの機能について。ざっくり言うと、タンパク質をつくります。
タンパク質は、マッチョになりたい人だけが摂るものではなく、細胞を構成する主成分であり、発酵において重要な役割を果たす酵素でもある(詳しくはDay3参照)。
それではいかにしてDNAがタンパク質をつくるのか順次解説。
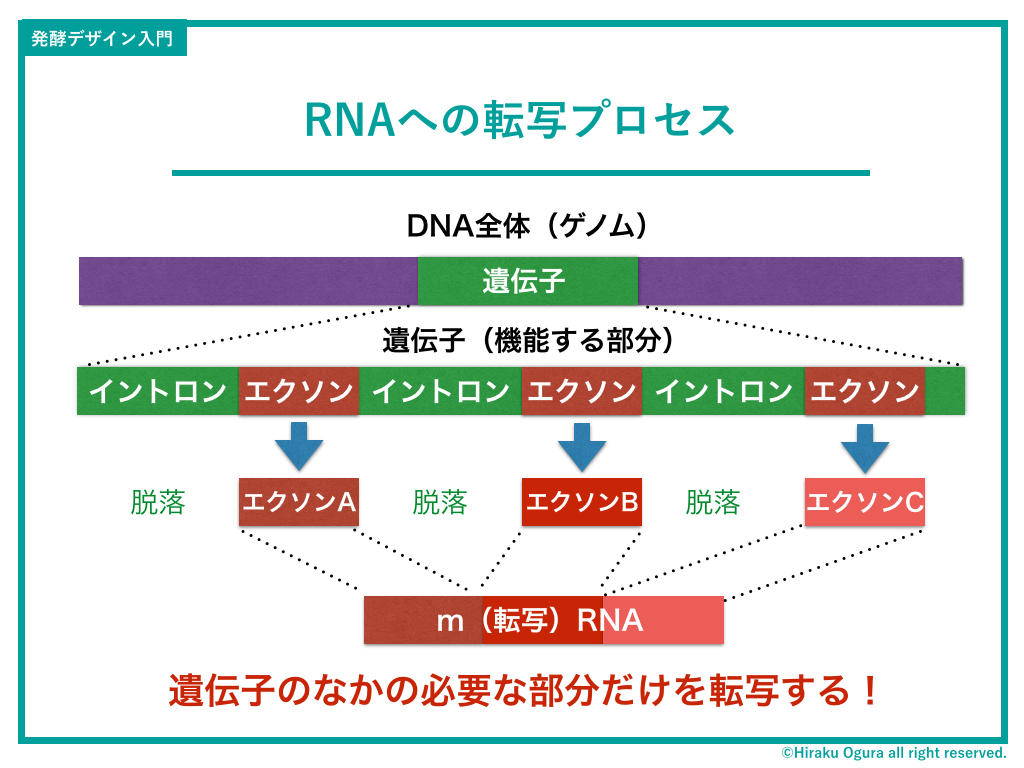
まず、DNA全情報(ゲノム)のなかのある特定の機能を持つ遺伝子部分が写し取られ、そこからRNAというDNAのCC(カーボンコピー)が作られます。この時にポイントなのが、遺伝子の情報全てを写し取るわけではなく、必要な部分(エクソン)のみ選択して写し取る、ということです。
「じゃあなんでこのイントロンとかいうわけわからんコードがあるんだ?」
知らねえよ!こっちが聞きたいぐらいだよ!
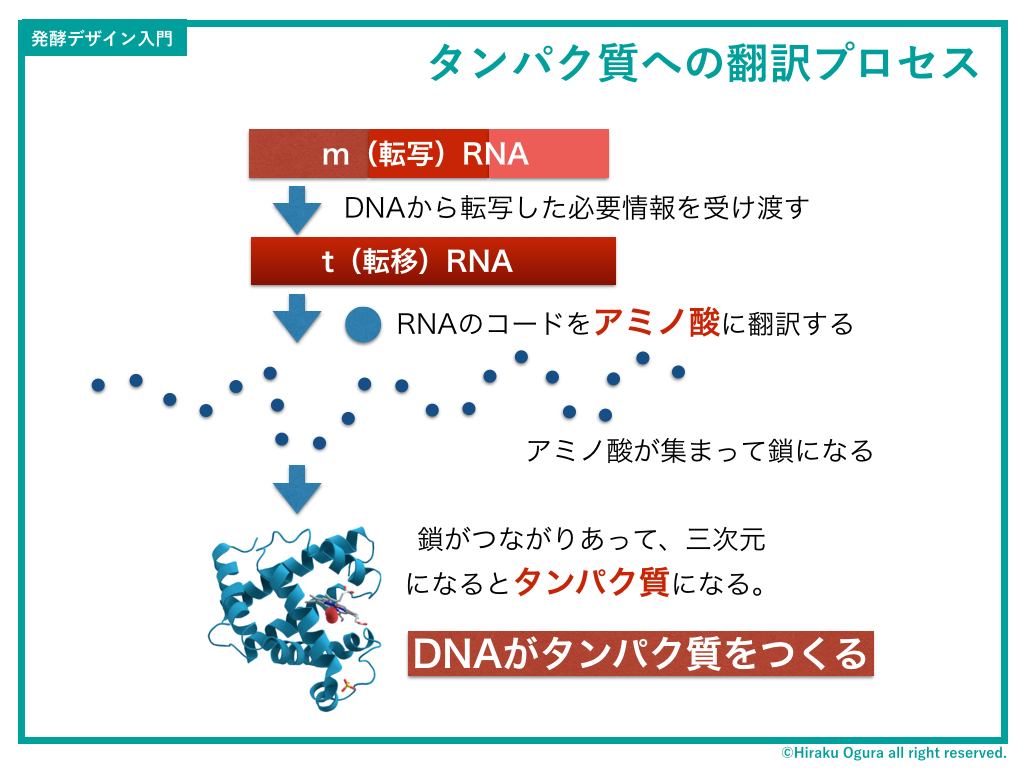
細胞の核周辺でできたRNAは、細胞のなかの工場(Day3参照)に移動し、そこでタンパク質をつくります。そのプロセスがこちら。
RNAに写し取られた AGCT…というコードが、三文字1セットでアミノ酸になります。
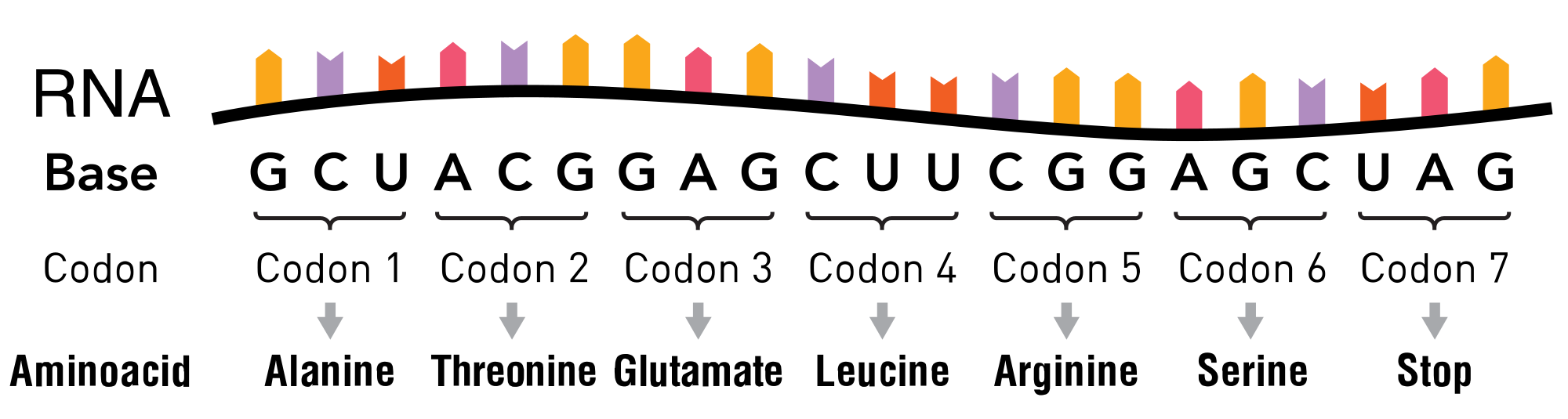
こんな感じ(ちなみにDNAがRNAに転写される時、T(チミン)がU(ウラシル)に変化します。ややこしいね)。上の図でいうと、GCUがアラニン、ACGがトレオニン…そしてUAGで作動停止、というように実際にプログラミングコードから物質(アミノ酸)がつくられていくわけです。
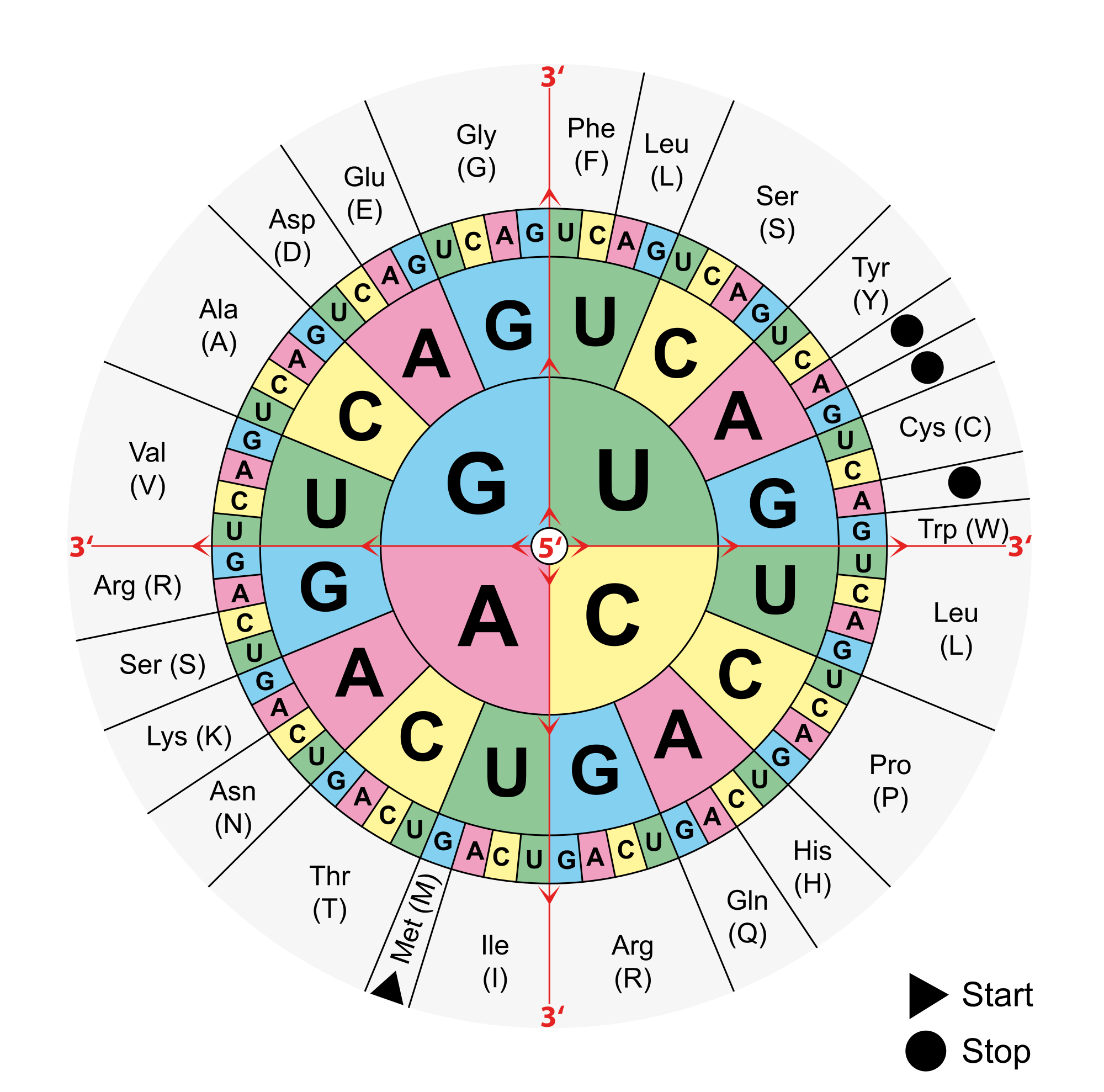
これがRNAコード=アミノ酸の対応表。
科学者のジョージ・ガモフが暗号解読に成功したものです。よくできてるねえ…
もっかいこのスライドに戻ります。
RNAからつくられたアミノ酸がたくさんつながって鎖状になります。このアミノ酸一個一個には「引っ張られる方向」があり、アミノ酸がいっぱい集まると、それぞれが自分の方向に引っ張られることで、勝手にクルクルと巻かれて三次元構造になります。
この三次元構造になったアミノ酸の集合体をタンパク質と言います。
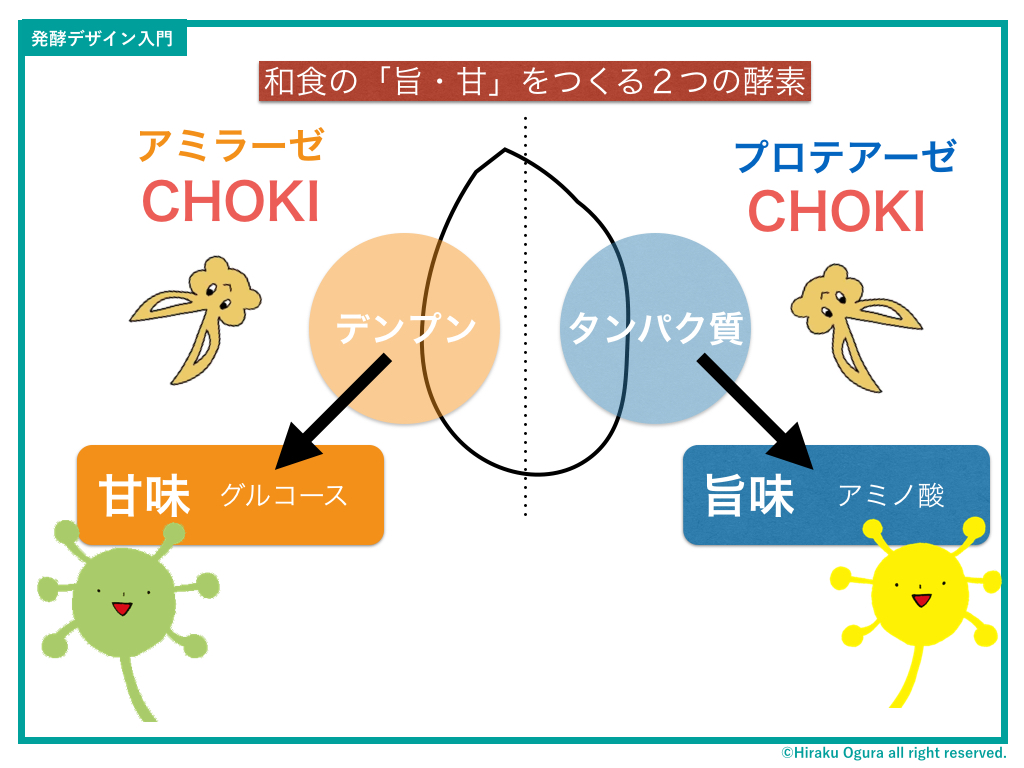
そしてここでついに「発酵のひみつ」の一端が分子レベルで明かされる…!
発酵菌の酵素によって、タンパク質がアミノ酸に分解されるとDay2で説明しました。これはつまり、DNAがやることを逆行しているわけですね。発酵によって分解されたアミノ酸は、人間の細胞を再生産する最小材料になるわけなので、カラダにとって絶対必要な物質になるわけです。だから、(必須)アミノ酸を摂るとカラダが喜ぶ。
「ヤバい、これ必要なヤツやった〜!」

では次行こう。
生命をつくる最小単位=アミノ酸&タンパク質をつくるDNAは、同時に自分で自分を複製=コピーする機能も持っています(ちなみに上の画像は今は亡き天才デザイナーの野田凪さんによるYUKIのPVより)。
生命の代謝活動とは、詰まるところ「細胞の再生産」です。
その細胞の再生産が行われる起点が、DNAの複製。DNA(設計図)が複製されることで、生命が複製される。

DNAの複製はなかなか奥が深い。
完コピ=有糸分裂と、かけ合わせコピー=減数分裂の2パターンがある。
ざっくり言えば、無性生殖(いわゆるクローン)が有糸分裂であり、本家EXILEやAKB48から分裂していくグループのようなもの。
対して有性生殖が減数分裂であり、ジャニーズファミリーから生まれる新グループのようなものだ(とか言うとアイドルファンから反論がいっぱい来そうだが、なんとなく察して!)。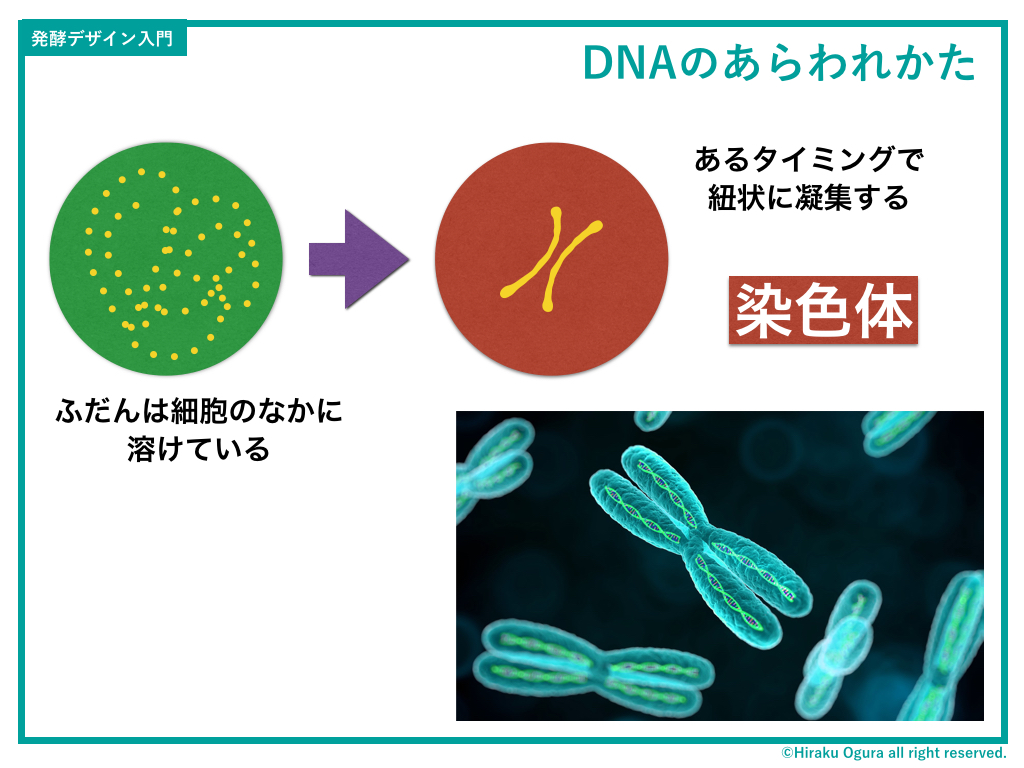
ではDNAの複製の具体的解説に入る前に、DNAの「しまわれ方」を説明する。
ふだん、DNAは細胞のなかに溶けた状態のなかで存在しているのだが、複製が始まるタイミングになると、糸状のかたちに集まって顕在化する。これを「染色体」と言う。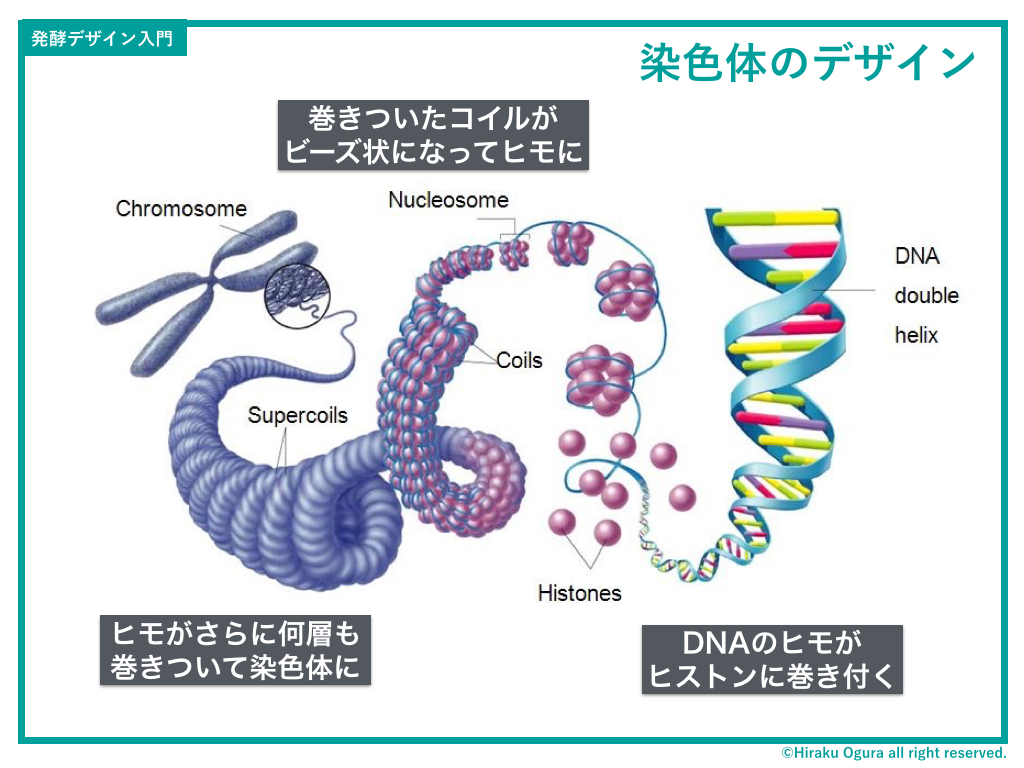
染色体のデザインはこんな感じ。ざっくり言うと、DNAの二重らせんの長いヒモが何重も巻き付いたヒモがたくさん集まってまたヒモになり、そのコイルがさらにヒモになって染色体になるという…
というヒモの無限地獄。
生物のこの「生命情報の超絶Jpeg圧縮」、誰得なの…?
ワークショップ:DNAを組み立ててみよう!

最終回のテーマはDNAということで、みんなで実際にDNAの模型を組み立ててみました。
リン酸と糖をつないで骨格をつくり、そこに塩基をはめ込んで…

長ーーーーく伸ばし、

グリッとねじる。キレイな二重らせん…!

こっちはイギリス製のすげー高いヤツ。それぞれのパーツが分子構造を模している。
穴の形にしたがってパーツをはめ込んでいくと、勝手に二重らせん型になる。各パーツの分子結合の位置を指定することで、二重らせんのカタチがデザインされる。

DNAがいっぱい!カッコいい!
複製と突然変異のあいだ
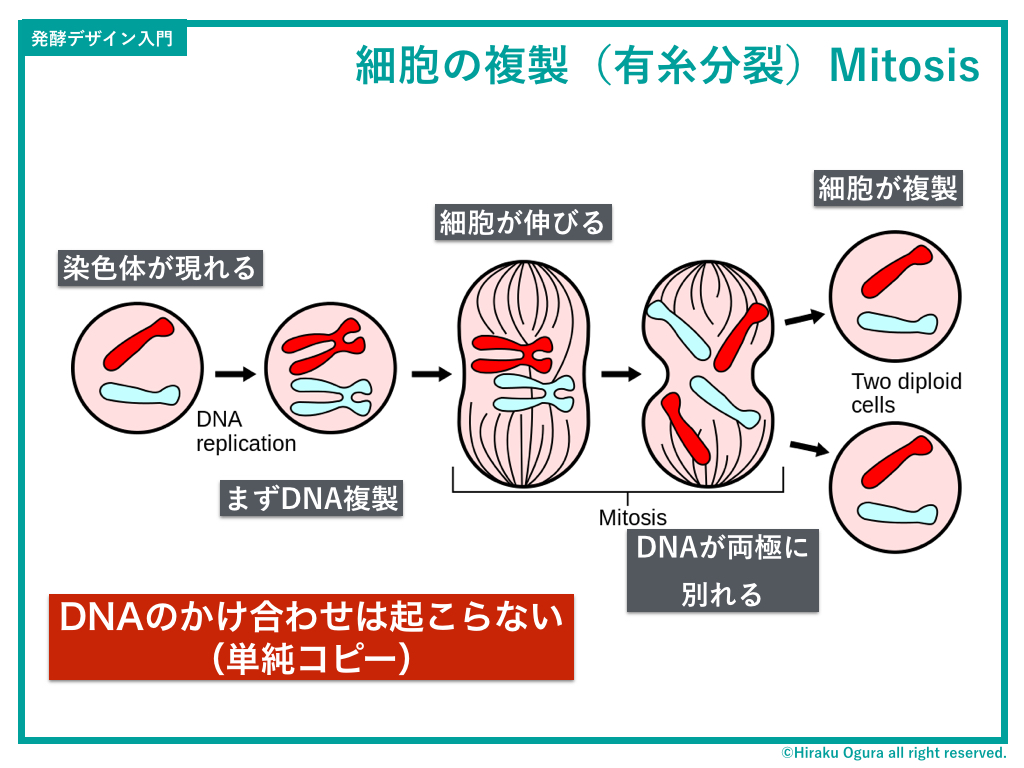
ではいよいよDNAの複製方法を解説するぞ。まず完コピ=有糸分裂から。
細胞のなかに染色体がペアであらわれ、そのペアが1つの細胞内で分裂し、その後に細胞がビヨーンと伸びて、真ん中でちぎれ、細胞が2つに分裂する。
このやり方のメリットとしては、速い、安定している、ミスがないという牛丼チェーンみたいな感じになっている。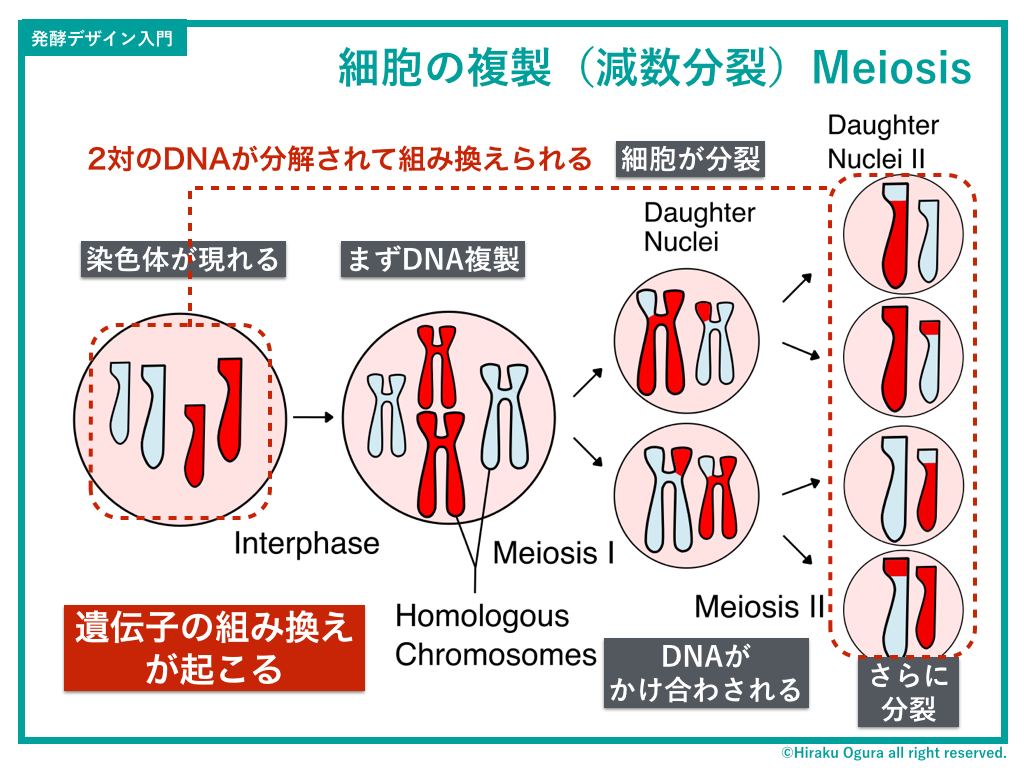
次に減数分裂。細胞のなかに染色体のペアが二組あらわれ、その二組がそれぞれのDNA情報の一部を取り替えた状態で分裂し、さらにそれをもう一度分裂させることで、異なる4つの染色体ペアをつくりだす。SMAPとTOKIOがかけあわされることで、V6と嵐とKinki kidsとタッキー&翼が生み出され、そこからKAT-TUNと関ジャニとHey!Say!JumpとSexy Zoneが生み出され…という具合で、同じ系統に属しながら、個性の違う個体が生み出されていく。
このやり方のメリットは、言うまでもなく突然変異=多様性を生み出すことになる。
しかし、デメリットとしてはよくコピーが失敗したり(Kiss-Myとか?)、バグが発生したりとか(裸で公園を走り回ったりとか)、個体が死ぬと同じものは生まれない(SMAP…!)などがある。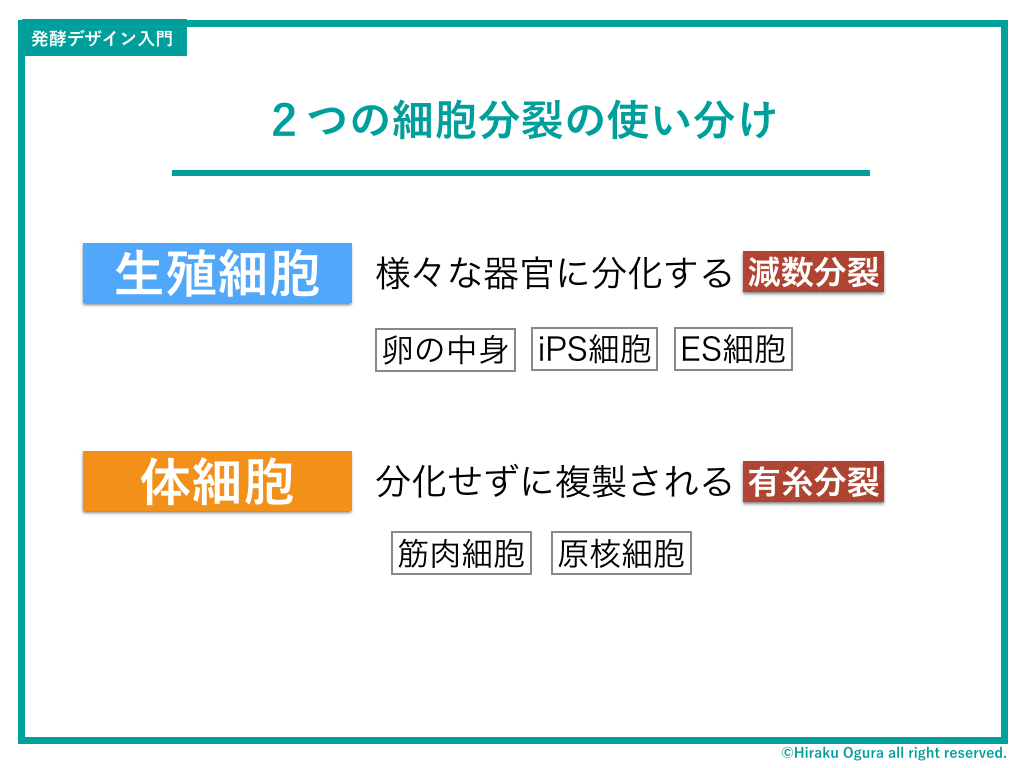
ちなみに僕たち人間を例にとってみると、この2つの複製方法を併用している。
卵子と精子が出会った細胞=受精卵は減数分裂で増える。そして一定数以上カラダができあがると、今度は各器官の細胞は有糸分裂で増える。
よくスキンケアの広告とかで「お肌の新陳代謝が〜」と言っているが、あれは「肌細胞の有糸分裂」がいかにスムーズに行われているかどうかなのであるよ。
ちなみにDNAの存在に初めて気づいたのはメンデルなのだけど、それはエンドウマメをかけ合わせるといつも4対の個性の違う個体があらわれる=減数分裂を発見したから。
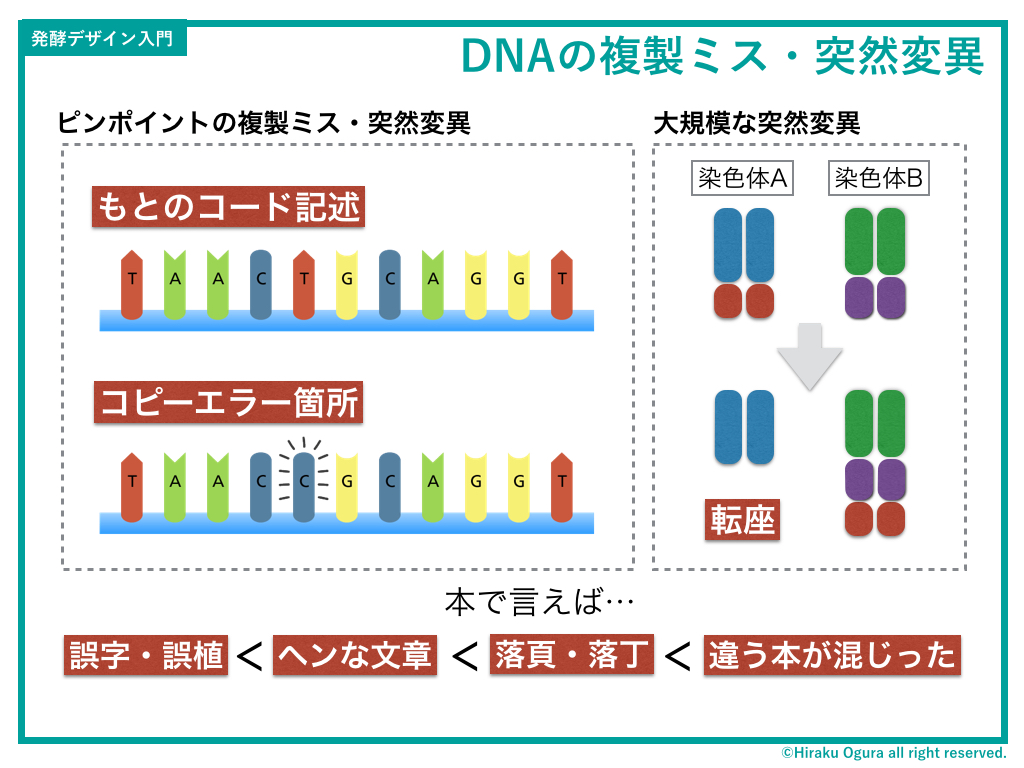
次にDNAの複製ミス=突然変異について。
僕たちのカラダのなかでは毎日膨大なDNA情報がコピーされているわけだが、当然そこにミスも起こる。しかしこのミスこそが進化にとって重要なのね(そうしないと永遠に原始生物がコピーされるだけじゃん)。
けれども。確率論だけでいうと、突然変異はほとんど病気や生殖不能の原因になる。
そこで「基本バグを防ぎつつ、ちょっとだけバグを許す」という難しいオペレーションが必要になる。細胞内には、単純なDNAのスペルミスを校閲するガールが配属されているので、ほとんどのバグが取り除かれる。しかしごくまれに、センテンス自体が入れ替わる大規模なスペルミスや、染色体のペア数が狂ってしまう凶悪なバグが発生する。
染色体は基本的に二本対なのだが、1本だけになったり3本だけになったりする。23ペアある人間の染色体のうち、21番目の染色体が3本になるとダウン症が発生する。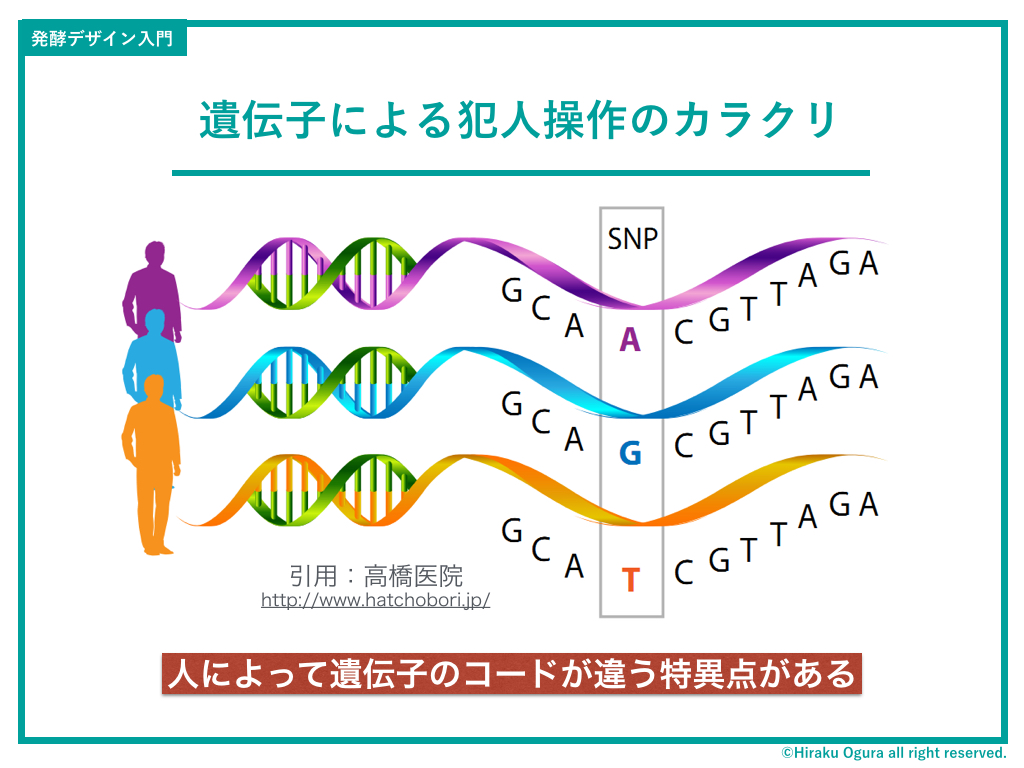
例えばAさんとBさんのDNAコードの99.9%は一緒。
なんだけど、ほんのちょっとだけ「人によって記述が違う部分」があります。これをSNP(Single Nucleotide Polymorphism)と言います。
で。
このSNPがよく刑事ドラマで出てくる「DNAによる犯人の特定」の原理だったりします。人によって違うある部分がAかGかTか。一箇所だけだと特定できないのですが、それを何箇所かピックアップすると「ほぼその人にしかないSNPの組み合わせ」があらわれるわけです。
ネット上でオーダーできるDNA解読サービスも、基本的には同じ原理で行われます。で、このSNPの原理を応用するとだな…
ガンや難病のリスクをDNA情報から予測することができる。
例えば、人間の12番目の染色体のある特定箇所がGだと酒に強く、Aだと下戸、というように、コードからその人間の機能を解読することができます。
ほら、よくプログラマーが気になるWEBサイト見つけたらそのサイトのソースを表示させて構造を分析してたりするでしょ。ああいうことが人間の遺伝情報でもできるよってこと。
ただ、DNAの情報だけで人間の健康や体質全てが決まるわけではない。その人の年齢や生活習慣によって、遺伝子機能のスイッチがOFFになったりONになったりする。
・遺伝子の機能そのものを調べる=ゲノミクス
・遺伝子の機能のON/OFFを調べる=エピジェネティクス
というように、DNAにまつわる研究領域も分化している。
(ちなみにエピジェネティクスの領域はほとんどが未知。これから研究者になりたい人はここ掘ると面白い発見ができると思うよ)
それではトピックスをよりリアルな世界に移していこう。
オーガニック食に興味を持っている人、あるいは生命工学の最前線にいる人がアンテナを張っている「遺伝子組換え」技術とは何か。
一言で言うなら、人為的にDNAに突然変異を起こさせることと定義できる。
つまり、遺伝情報の書き換えを行い、バグ(←ただし人間の役に立つヤツ)を誘発する。この技術が登場したのは、1970年代のことだった。
40年前と今では、技術の精度にずいぶんと差がある。昔はめちゃくちゃ大変だったが、最新技術を使うと比べ物にならないほど効率的かつピンポイントに遺伝子組換えを行うことができる。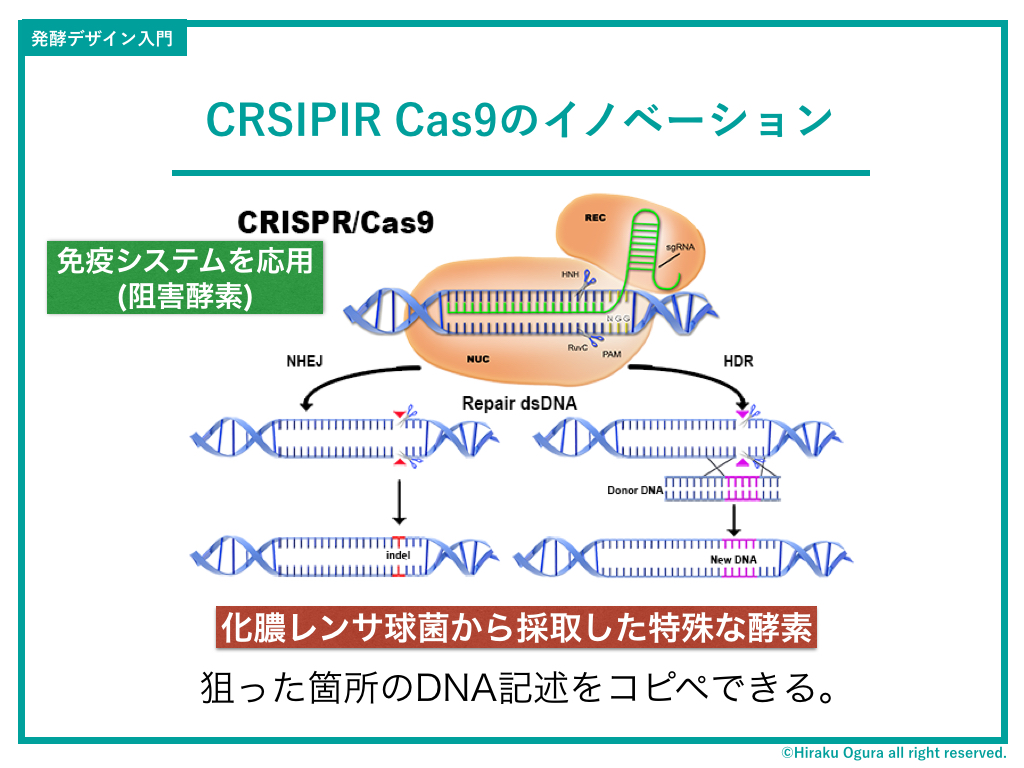
遺伝子組み換え技術の最新型、CRISPIR Cas9(クリスパー・キャスナイン)。
これはざっくり言えば「化膿レンサ球菌」という猛毒のばい菌の酵素を応用して、DNAのプログラミングコードを自由にコピペするという技術のこと。こいつを使ったコピペ術を『ゲノム編集』と呼んだりもする。
プログラミングするように、生命をデザインする。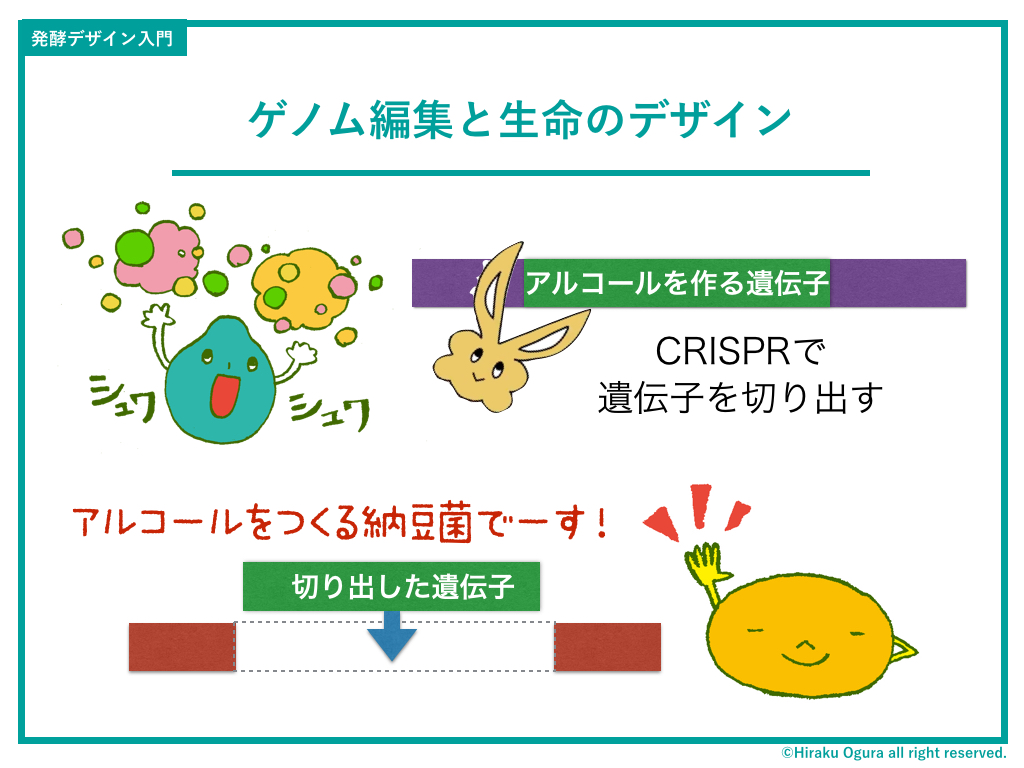
ということでクリスパーの機能をもうちょい解説。
酵母のDNA全情報(ゲノム)のなかから、アルコールをつくる遺伝子部分をカットして、納豆菌のDNA配列のある部分にペーストする。
すると、アルコールをつくる納豆菌がデザインされてしまう。
これが最新の遺伝子組換えの仕組み。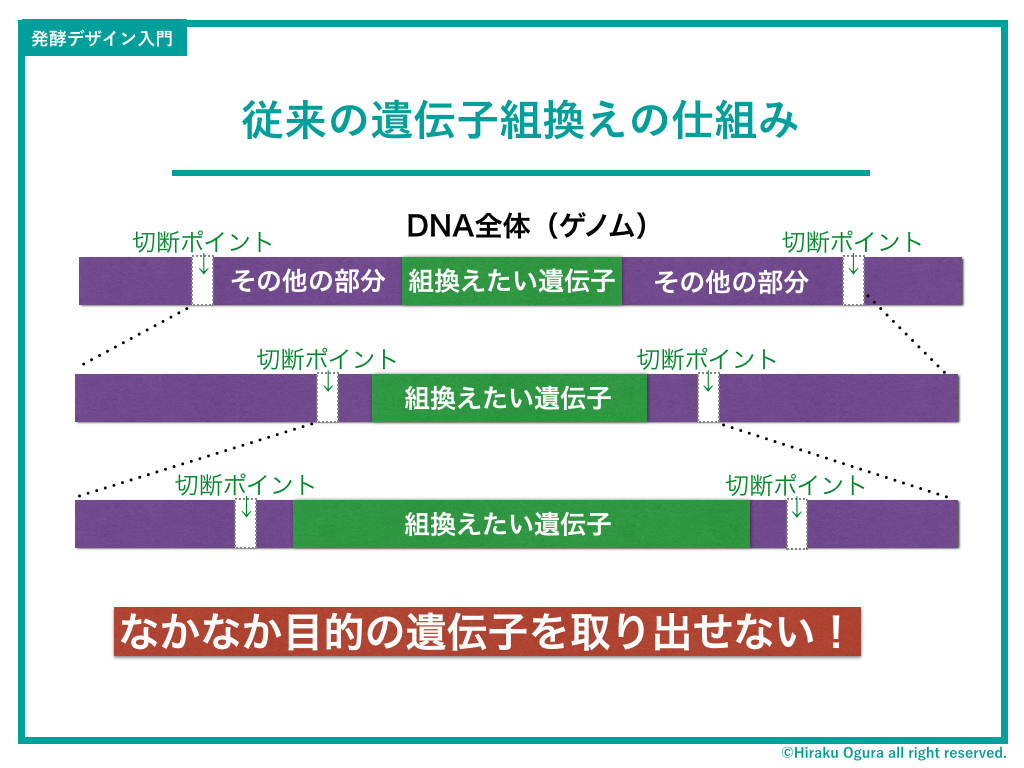
実は従来型の遺伝子組換えも同じ原理なんだけど、違うのはその精度。
クリスパーが超ピンポイントでレイアウト自由だとすると、従来型は取り出したい遺伝子を何ステップもかけて絞り込んでいくという手間のかかるものだった(講座では従来型のやり方も解説したんだけど、長くなりすぎるのでブログでは割愛)。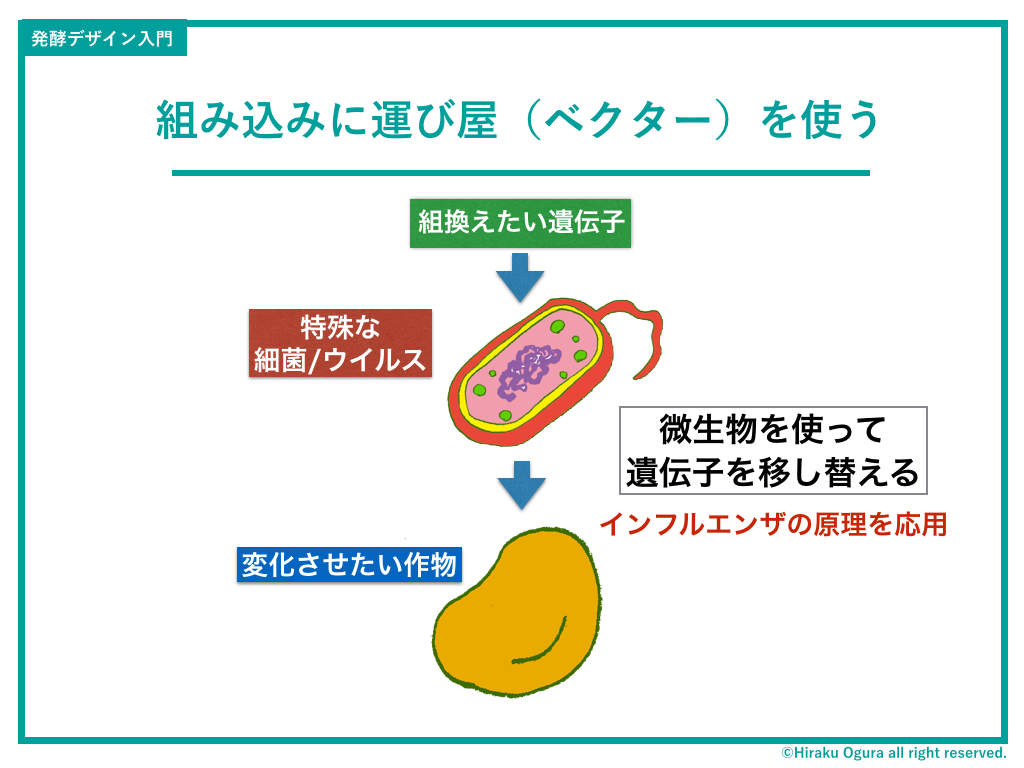
しかも狙った遺伝子を切り出した後がまた大変。直接ペーストできないので、特殊な細菌(アグロバクテリウム)やウイルスを運び屋として切り出した遺伝子を、組み合えたい作物や菌に移し替えなければいけない。これもよく失敗したりするので面倒くさい。
現在バイオ業界はクリスパーの登場でめっちゃ盛り上がっているが、これは従来型よりもはるかに高精度かつ楽チンに遺伝子組換えができるイノベーションだからなのであるよ。
ある意味、クリスパーが生命における特異点(シンギュラリティ)になるかもしれないと一部の業界では噂されている。なぜかというと…
前述の「酵母菌の機能を埋め込んだ納豆菌」を動物に当てはめると、古代ギリシャ神話に登場するキメラ(異なる種を合体させた生き物)を実現することができる。
ていうか、今までもキメラの合成は実験されてきたのだけど、免疫機能にジャマされてうまくいかなかった(免疫機能についてはDay4後編を参照)。
原理的には空飛ぶ馬だろうと、肉を食べないで草を食べるライオンだってデザインできる。
ならもちろん人間もデザインできるよねって話にもなるのは必然。
受精卵の状態で、DNA情報を編集すれば、下戸体質を修正し、ガンにかかる要素を排除し、なんならアタマよくなる機能にスイッチを入れたり、100メートル10秒で走れる筋肉機能を追加したりできる。
このイノベーションに、もちろんITの巨人たちもアクションを起こしている。
Googleとamazonが狙っているのは「ゲノム編集とビッグデータの融合」だ。クリスパーの登場によって、今まで物理的障害にジャマされていた遺伝子組み換えが「純粋なデータサイエンス」に近づくならば、「遺伝子情報のデータベースを構築&クラウド化」をした者がバイオイノベーション戦争に勝利することができる。
例えば近未来。MADなバイオサイエンティストと化したヒラクが、年老いた愛猫の寿命を100年延ばしたいと思ったら、Googleの「遺伝子データベース」から「寿命延ばす遺伝子コード」を5ドルでダウンロードして、クリスパーを使って猫ちゃんの遺伝子組換えをする…という未来が待っているかもしれない。

超国家規模の巨大な流れが起これば、ボトムアップ型の流れも起きる。
それがまさにこの講座のような「DIYバイオムーブメント」。
(ちなみに僕がテキトーに名付けたんじゃなくて、ほんとにそう呼ばれ始めている)
「長いものに巻かれる」的なスタンスで世間に振り回されるならば、そのナレッジを自分なりに実践してみようではないか…!と思うのが人の良心及び好奇心というもの。
昔だったら何百万円もした実験機材の値段が、世界中のバイオハッカー達の努力の結果下がりまくり、オープンソースでDIYできるようになってきた今、研究機関に所属していないフツーの個人でもバイオテクノロジーの研究を実践することができるようになってきた。
この状況を活かして、自分の暮らしに必要な技術をつくることもできるし、実践で得た知識をもとに、大学や行政、企業とコミュニケーションを取ることもできる。
Day1の話に戻るけれども、どんなにお金や人材の豊富や研究機関でも「科学のリスク」を回避することはできない。そのリスクを軽減して、テクノロジーを明るい未来に役立てるためには、フツーの人である僕たちのリテラシーと好奇心にかかっている。
テクノロジーは専門家だけのものではない。僕たちが僕たちなりのやり方でテクノロジーを身に着け、自分の現実の暮らしに翻訳していかなければいけない。
ということで前5回のまとめ。
今回の講義を通して「ほしい未来をつくるためのリテラシー」を定義してみました。
新しいものよりも「自分に必要なもの」を自分で考える。その考えを仲間とシェアして社会をより良く。このナイスなスパイラルの起点に、あなたがなってくれたらいいなと思うのだぜ。

『発酵デザイン入門講座』第一期に集まってくれたみんな、ほんとにありがと〜!
DNAと発酵食品とともに、はいチーズ!近々同窓会やろうぜー。
photo by 吉川修平 & 高橋奈保子 & 井上薫 ありがとー!